全量安装包安装
仅针对中国大陆用户
一、安装FluxSD
1. 安装 docker
Open https://www.docker.com/ , download docker and install it.
2. 下载安装包
Fluxsd安装包下载地址:https://github.com/tonera/fluxsd/archive/refs/tags/v1.0.1.zip 生成器Generator下载地址:https://github.com/tonera/fluxsd/releases/download/v1.0.1/generator.zip
3. 将下载下载的两个zip文件存在一个剩余空间较多的目录,如fluxsd,并解压缩
此时目录结构如下 fluxsd
-- fluxsd #将fluxsd-xxxx.zip文件解压缩后,文件夹改名为fluxsd
-- generator #AI图片生成器
4.配置.env文件
进入fluxsd/fluxsd目录,将.env.example 文件复制为.env文件,并打开文件,修改
APP_HOST={你的ip地址}
APP_LOCALE = zh例如你的IP地址是192.168.31.17 则修改为
APP_HOST=192.168.31.17
APP_LOCALE = zh5.打开防火墙端口
请根据自己的操作系统,允许对以下端口的访问 8000 8080和6379
在Windows系统上打开以上端口,你需要具备管理员权限,并按照以下步骤操作:
-- 打开Windows防火墙设置:首先,打开“控制面板”,选择“Windows防火墙”。
-- 进入高级设置:在防火墙设置中,找到并点击“高级设置”以进入高级安全Windows防火墙。
-- 新建入站规则:在高级安全Windows防火墙中,点击“入站规则”,然后点击“新建规则”。
-- 选择端口:在新建入站规则向导中,选择“端口”,并指定端口号为8000。 设置规则:选择允许通过此端口的连接,并设置相应的作用域和条件。 完成规则创建:命名新规则并保存设置。
按以上步骤继续新建8080和6379端口的入站规则
Linux系统
sudo iptables -A INPUT -p tcp --dport 8000 -j ACCEPT
sudo iptables -A INPUT -p tcp --dport 8080 -j ACCEPT
sudo iptables -A INPUT -p tcp --dport 6379 -j ACCEPT如果你使用的是firewalld,可以使用以下命令:
sudo firewall-cmd --permanent --add-port=8000/tcp
sudo firewall-cmd --permanent --add-port=8080/tcp
sudo firewall-cmd --permanent --add-port=6379/tcp
sudo firewall-cmd --reload如果是其他操作系统,请自行搜索配置方法。
6.启动fluxsd
打开终端窗口执行以下命令,(Windows系统请在目录下右键打开PowerShell终端窗口)
Linux或者Mac
docker-compose upWindows系统
docker-compose.exe up打开: http://{你的ip地址}:8000 开始使用
注意:至此,FluxSD已成功安装,如果你希望利用本地计算机生成图片,那么请继续安装图片生成器。安装前请确认自己的显卡是Nvida显卡,且拥有8G以上显存。
二、安装AI图片生成器(仅支持Nvidia显卡)
1.安装Python 3.11
-- 对于Windows系统,请在windows应用商店搜索python3.11安装。
-- 对于Linux系统,请自行搜索各系统安装方法,或者参考官方网站。 https://www.python.org/downloads/
2.安装AI图片生成器
打开终端窗口,进入之前下载的安装包所在目录(Windows系统请在目录下右键打开PowerShell终端窗口)
Linux系统(pip或者pip3 )
cd fluxsd/generator
python -m venv .venv
. .venv/bin/activate
pip install -r requirement.txt -i https://mirrors.aliyun.com/pypi/simple如果是windows系统,则执行以下命令 (如果pip可执行文件不存在,请尝试使用pip3)
cd fluxsd/generator
python -m venv .venv
.venv/Scripts/activate
pip install -r requirement.txt -i https://mirrors.aliyun.com/pypi/simple你有可能会遇到无法加载 .ps1 文件的错误提示,这是因为Windows的安全策略阻止了脚本运行,你需要以管理员身份执行
Set-ExecutionPolicy Unrestricted来解除此限制。
注意:因为其中一个软件包的版本过低,所以请务必修改生成器目录下
.venv\Lib\site-packages\basicsr\data\degradations.py
将第8行
from torchvision.transforms.functional_tensor import rgb_to_grayscale改为:
from torchvision.transforms.functional import rgb_to_grayscale最后,下载你的第一个图片大模型:
将下载下来的文件:sd_xl_base_1.0.safetensors 保存在 fluxsd/generator/models 目录下。
3. 安装Torch
注意: 只支持Nvidia系列显卡
打开 https://pytorch.org/ 并按照自己的实际情况选择相应的配置

例如我的显卡CUDA驱动是12.4,则执行以下命令安装
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
如何查看自己的CUDA版本?
nvidia-smi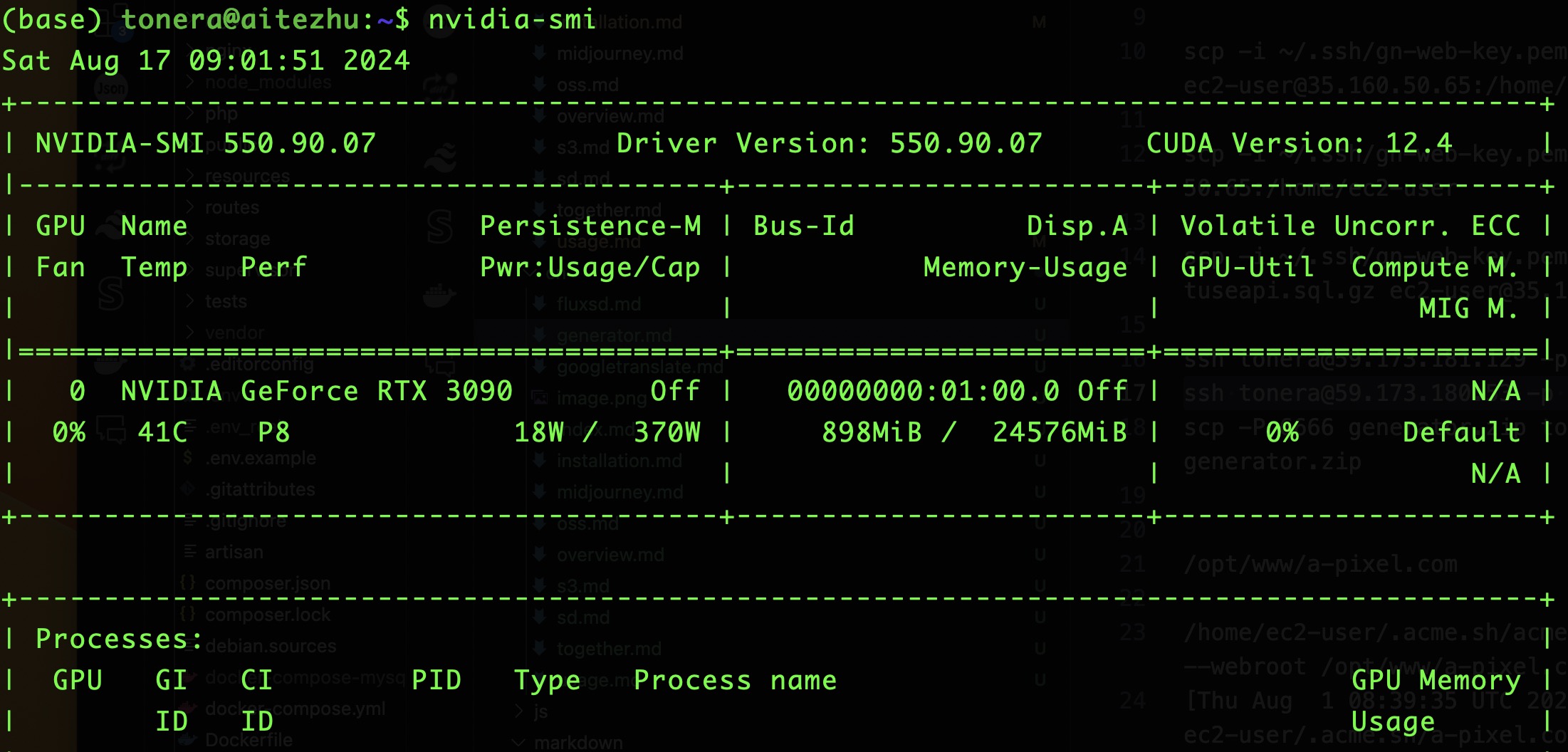
其中右上角 CUDA Version: 12.4就是版本号。
4. 配置
在浏览器打开Fluxsd系统,点击:配置,复制配置 -> 图片模型 -> 本地 -> 图片生成器配置文件,将文本框的内容复制到生成器config目录下mk_config.ini文件中
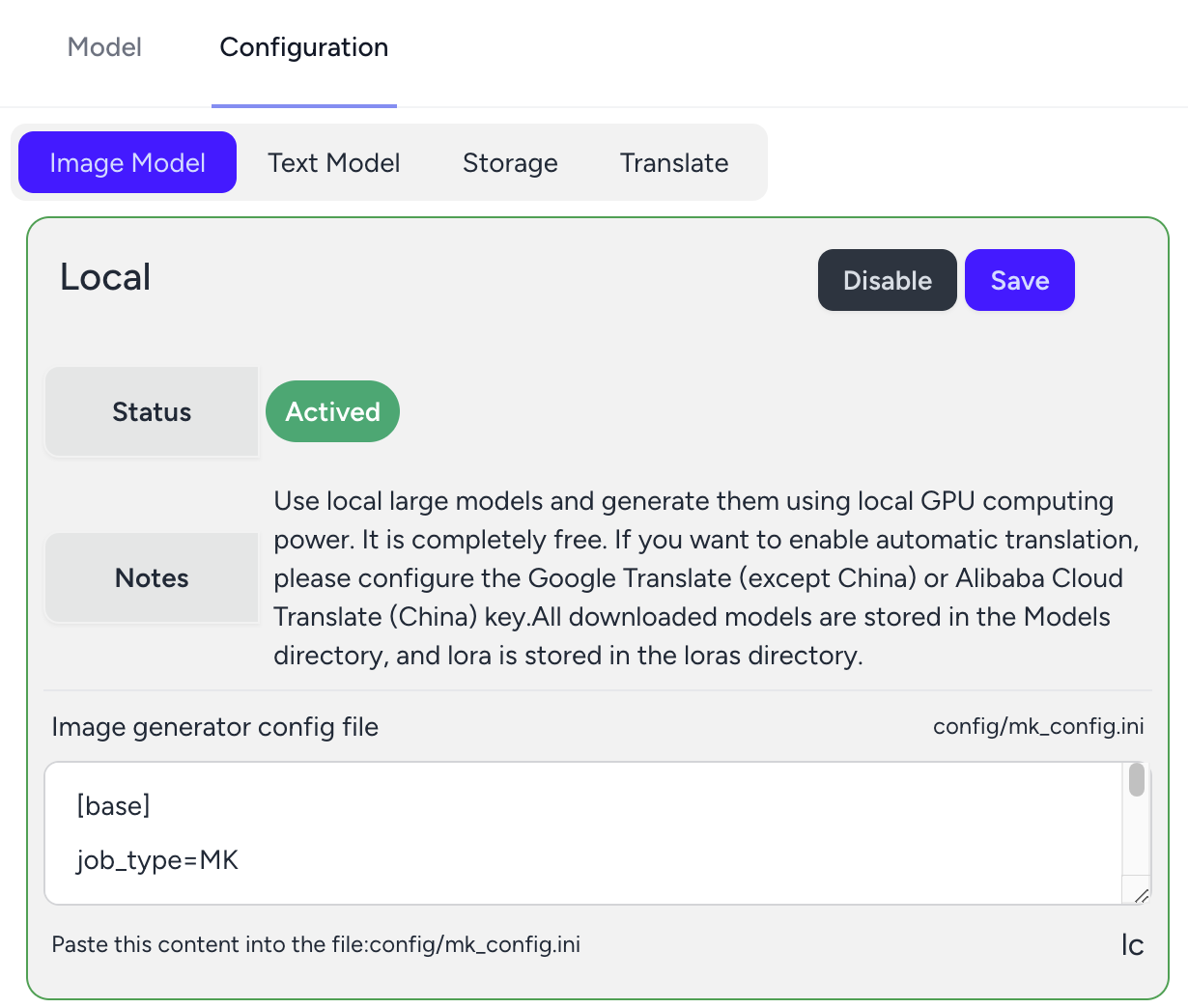
5. 启动生成器
python Service_atz2.py base请注意,每次启动生成器时,都需要先激活python环境再执行此脚本。
cd generator
. .venv/bin/activate
python Service_atz2.py baseWindows需要把
. .venv/bin/activate换为
.venv/Scripts/activate三、开始使用
FAQ
-
Windows下执行生成器脚本遇到错误:
INFO OSError: [WinError 126] The specified module could not be found...“...\lib\site-packages\torch\lib\fbgemm.dll"从 https://www.dllme.com/dll/files/libomp140_x86_64/00637fe34a6043031c9ae4c6cf0a891d/download 下载 libomp140.x86_64.dll 文件保存到/windows/system32目录下。
-
错误:“numpy.core._exceptions.MemoryError: Unable to allocate 1.04 MiB for an array with shape (370, 370) and data type float64” 内存不足,请增加虚拟内存空间大小。